Pro
Starting out or only need basic functionality?
Enterprisepopular
Want to unleash the full power of Snappic?
Enterprise Plus
Scaling your business and need higher management options?


Are you ready to catapult your photo booth business into a realm of unprecedented success in 2024? Let's cut to the chase - you need a powerhouse tool that not only matches your am Read More

Have you ever found yourself stuck, feeling like your photo booth offerings are becoming a bit... stale? Ever looked at competitors and wondered how they're creating those jaw-drop Read More

We get it. Setting up an event can be a daunting task, especially when you're pressed for time or working with last-minute bookings. And let's not even get started on the challenge Read More

A wedding day is more than just an occasion; it's an orchestra of love, joy, and timeless moments. While couples are busy drafting their fairy tale, photo booth businesses have a g Read More
In today's rapidly evolving digital world, the business of memories also needs to innovate. If you are a photo booth owner looking to elevate your offerings, static and animated ov Read More

When it comes to immortalizing the magic of special events, photo booths and 360 video booths have emerged as an indispensable tool. And now, to turbocharge this experience and cre Read More
The photo booth industry is on fire, and the popularity of photo booths & 360 booths at events is skyrocketing! From weddings and parties to corporate events and festivals, photo b Read More

We all know that AI (Artificial Intelligence) is taking the world by storm. It has become an essential tool for businesses in most industries, and the Photo Booth industry is no ex Read More

The annual Photo Booth Expo in Las Vegas is the world's largest trade show for photo booth owners and operators. It's a momentous gathering of like-minded individuals who strive to Read More

With all those event bookings, the last thing you want to do is stress about customizing your events so that they are branded according to the theme. So why not let Snappic help yo Read More

Are you struggling to find ways to innovate your photo booth offering? The Photo Booth industry is constantly changing, with new concepts and ideas popping up all the time.If you’r Read More

Photo booths have always been a popular fixture at events, allowing guests to have fun and capture memorable moments.However, photo booths are not a new concept, and the usual stil Read More

Studio Z believed in the power of digital photo booths but kept running into difficulties with their gear and providers.While trying to do boomerangs on the PC, they found the proc Read More

There’s no doubt that 360 Photo Booths are all the rage these days. Whether your clients want to add a unique touch to their wedding, throw a killer party, or get some fantastic br Read More

Do you feel like your photo booth business could be earning you way more money? Are you struggling to stay ahead of the competition in your area?Snappic wants to help you out! Our Read More

With vaccines rolling out, in-person events are slowly starting to return. This, however, does not mean that we can throw away our masks and socialize like it’s 2019. The big quest Read More

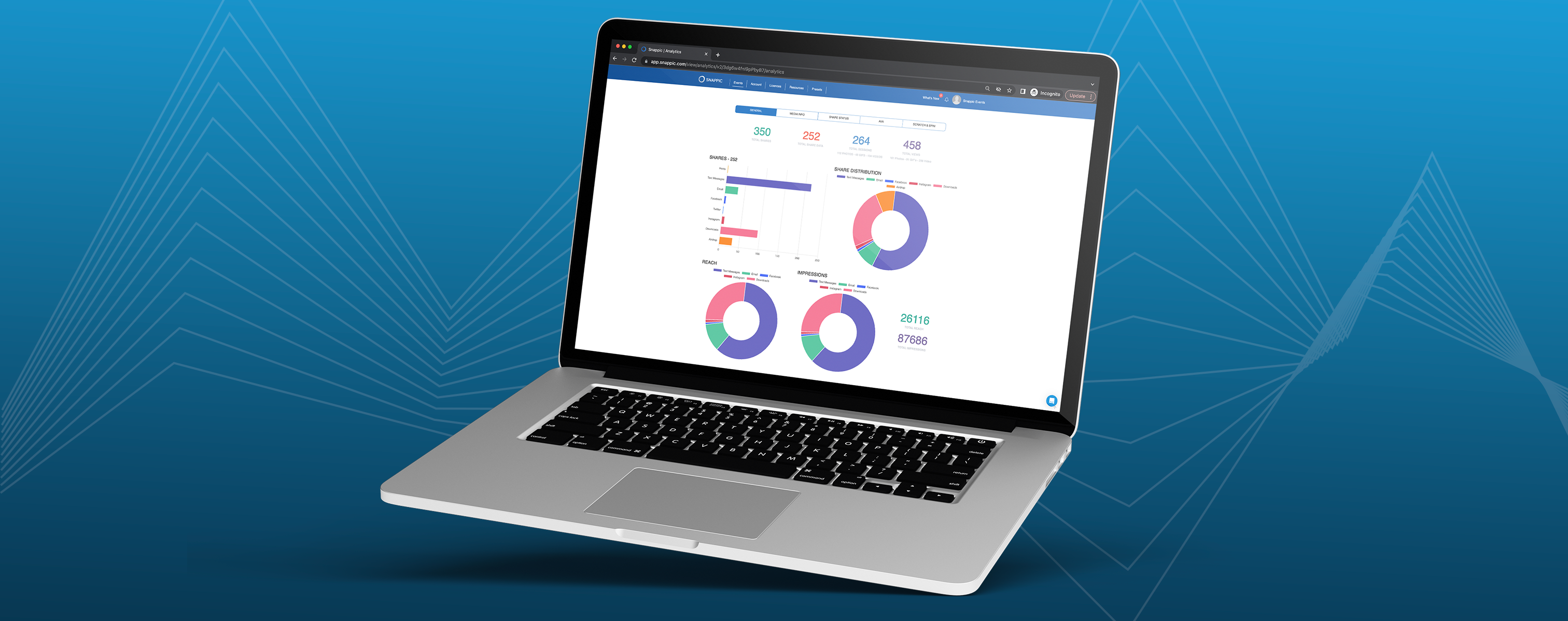
Snappic is an industry-leading iOS-based photo booth software.We have a long list of features that will help your photo booth business be the best it can be..We are also constantly Read More

And living in a society captivated by the likes of Instagram, Snapchat and memes, it’s no wonder that photo booths have seen a resurgence in recent years.But leveraging this visual Read More

Sometimes called participation marketing, experiences that are designed to promote a product or brand can make all the difference in getting you noticed. To put it simply, when you Read More

Want to add something a little more festive to your next event? Or transport your guests to a far away destination?Green screen photo booths are an excellent way to create a mement Read More






